The global Microsoft outage caused by CrowdStrike’s update is a clear reminder of how dependent we are on our interconnected digital systems.
A flawed update from CrowdStrike, a leading cybersecurity firm, led to disruptions in various sectors, including airlines and hospitals, highlighting the critical need for robust and fail-safe update mechanisms.
As we rely more on technology, these occurrences raise questions about our dependency on single providers and the adequacy of our current safeguards.
I wish to clarify that I am not assigning fault or blame to anyone. It is a known fact that no software is flawless, and occasional glitches are inevitable. Developing inline products presents significant challenges, yet they are indispensable for maintaining the security of our business.
In our last article, we discussed the importance of application security testing. Today’s Microsoft outage caused by a Crowdstrike update highlights the critical need for robust security measures to prevent such disruptions.
In today’s fast-paced digital environment, an update gone wrong can ripple through systems worldwide, causing chaos. CrowdStrike’s mistake demonstrates that even top cybersecurity companies are not immune to errors that have wide-reaching consequences.
We need to explore whether having multiple layers of checks can prevent such incidents and consider diversifying our providers to avoid single points of failure.
Given the widespread impact, ranging from operational delays to the potential for compromised security, it’s clear that organizations must reassess their update and cybersecurity protocols.
Enhanced monitoring, quicker response times, and diversified service providers could be key strategies to mitigate risks from future updates gone awry.
Overview of the Microsoft Outage
Today, a major outage hit various Microsoft services due to a flawed update from CrowdStrike. This incident impacted airlines, hospitals, banks, supermarkets, etc causing significant disruptions.
Our Windows PCs experienced issues such as the infamous BSOD (Blue Screen of Death). Core services like Microsoft 365, Teams, and Azure cloud services faced outages, leaving businesses and individuals unable to access essential tools.
According to The New York Times, the incident affected emergency services and multiple industries. 911 lines in several states went down, highlighting the severe impact on critical infrastructure.
At airports and banks, operations came to a halt. Many users reported that their computers became unresponsive, and some struggled to regain control over their devices. IT teams across various sectors scrambled to mitigate the effects.
Role of CrowdStrike in the Outage
CrowdStrike is a cybersecurity company. They issue software updates to protect systems from malicious attacks. On July 19, a single content update was released but led to a significant problem.
The update came from CrowdStrike’s Falcon software. Falcon is a cloud-based platform preventing breaches with integrated technologies like next-gen antivirus, endpoint detection, and cyber threat intelligence. Unfortunately, this update contained a defect that led to widespread issues.
The privilege and power of Falcon is well described in this article
This glitch caused significant disruptions and showcased the critical nature of cybersecurity solutions in today’s tech landscape.
CrowdStrike’s Response
After realizing the issue, CrowdStrike took immediate action. The company’s CEO tweeted about the incident and appeared on the sky news show to deliver a direct apology, reflecting the seriousness of the problem.
He has confirmed it wasn’t a security breach or cyberattack. It only affected Windows machines, with Linux and Mac systems remaining unaffected.
He has also released an apology statement this afternoon
CrowdStrike promised and rectified the flawed update as quickly as possible. They also provided support to affected users, ensuring that solutions were implemented to restore normal operations.
The company admitted responsibility, which is crucial in maintaining trust with users. By addressing the problem head-on and offering support, CrowdStrike aims to mitigate the negative impact and prevent similar issues in the future.
Affected Regions and Industries
Today’s Microsoft outage disrupted various regions and industries, highlighting the widespread impact of a single content update.
It’s a moment to reflect on how such an update can affect numerous sectors and individuals. Below, we outline the key areas and sectors impacted.
Impact on Airlines
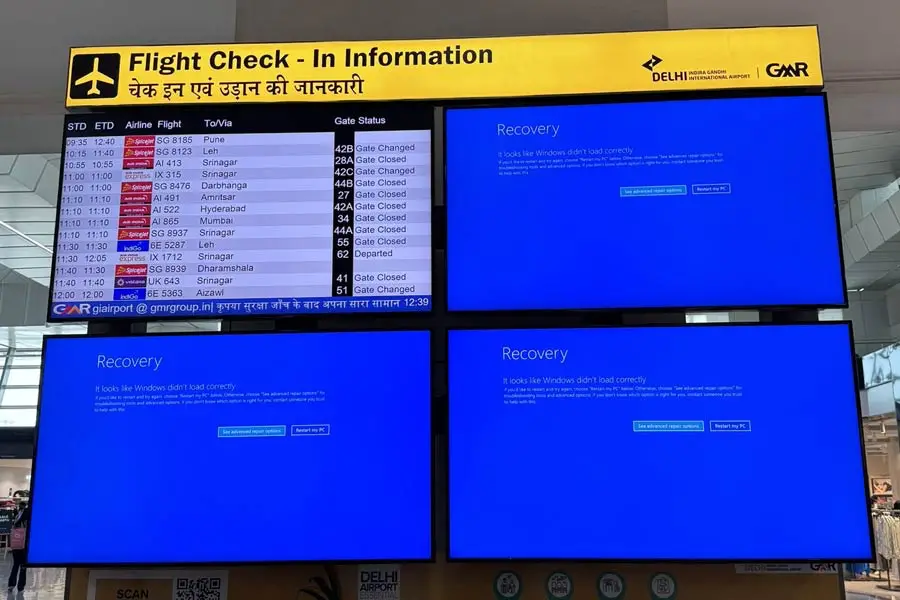
Airlines experienced severe delays and cancellations. Flights were grounded as airline IT systems, heavily reliant on Microsoft’s Azure cloud services, went offline. Major carriers faced operational challenges globally, with airports in the India, US, UK, and Australia being particularly hit.
Passengers faced extended wait times, and rebooking became a logistical nightmare. The loss in revenue for airlines and inconvenience to travelers highlighted the vulnerability of current IT systems.
Disruption in Financial Services
Several Banks and the London Stock Exchange experienced disrupted operations due to the outage. The financial sector relies on continuous IT services for trading, transactions, and customer service. With Azure services down, these operations were stalled.
Trading activities slowed, affecting market dynamics temporarily and banks struggled to maintain service continuity. Customers faced issues accessing their accounts, causing widespread frustration.
Healthcare and Emergency Services Affected
Healthcare systems and emergency services in the US and other regions were also affected. Hospitals and clinics relying on cloud-based applications faced challenges accessing patient data. This situation created a backlog in services and delayed medical procedures.
Emergency services, including 911 lines in several states, experienced outages, raising concerns over public safety. While these services were restored quickly, it underscored the critical need for robust backup systems.
Global Tech Outage Scope
The global nature of the outage meant that almost all regions were affected to some degree. Retailers and supermarkets relying on cloud services for transactions and inventory management faced operational hitches. Supermarkets in the UK and India reported some delays in processing payments.
In addition to the retail sector, various other businesses relying heavily on IT infrastructure found their operations significantly disrupted. This event showcased the global tech industry’s dependency on robust and uninterrupted cloud services.
Do we need better updates procedures?
The latest Microsoft outage, impacted by a CrowdStrike update, shows a pressing need for improved update procedures. Several emergency systems were affected, highlighting the critical need for reliability.
Key Points to Consider:
- Testing: Updates should undergo rigorous testing in diverse environments before release. This helps identify potential issues early.
- Staggered Rollout: Adopting a phased or staggered approach to updates can allow for monitoring and addressing issues in smaller segments, rather than affecting all users simultaneously.
- Clear Rollback Plans: Implement automated rollback to quickly revert updates if issues arise, minimizing downtime and maintaining system stability.
- Backup Systems: Maintain robust backup systems to switch to in case of update failures. This ensures continuous operation even during issues.
- Automated Monitoring: Integrating automated monitoring tools can help detect issues during and after updates, providing immediate alerts and insights for quick resolution.
- Vendor Coordination: For updates involving third-party vendors, better coordination and communication with vendors can ensure compatibility and address any issues that might arise.
- User Feedback: Encourage user feedback during update rollouts. This allows for rapid identification and resolution of problems.
| Issue | Recommended Procedure |
|---|---|
| Unreliable Updates | More thorough Testing |
| Widespread Outages | Staggered Rollouts and Rollback |
| Lack of Redundancy | Improved Backup Systems |
| Slow Issue Detection | Improved Monitoring and Encourage User Feedback |
It is also important to maintain thorough documentation of update procedures, known issues, rollback procedure and regularly reviewing them for improvements can help enhance the effectiveness and reliability of future updates.
These steps can lead to fewer disruptions and more reliable updates. By prioritizing these procedures, we can enhance the stability and reliability of our systems.
Should we depend on only single provider ?
Using one provider can make things simpler. We only have one contract, one bill, and one platform to manage. This can save time and make troubleshooting easier.
However, putting all our eggs in one basket can be risky. If the provider has an outage or security issue, like the recent Microsoft outage caused by a CrowdStrike update, it can impact all our services.
With multiple providers, we spread the risk. If one goes down, the others can keep running. This approach, known as a multi-cloud strategy, can improve uptime and reliability.
Costs and management are higher with multiple providers. We need different skills and tools for each one. Tracking usage and costs becomes more complex.
Pros of Single Provider:
- Simplicity: Managing a single cloud provider simplifies billing, management, and integration.
- Cost Efficiency: Potential discounts and lower overall costs by consolidating services with one provider.
- Integrated Services: Better integration between services, tools, and applications within the same ecosystem.
- Easier Management: Streamlined support and fewer administrative tasks as you deal with only one vendor.
- Performance Optimization: Optimized performance and reliability when all resources are from the same provider.
Cons of Single Provider:
- Vendor Lock-In: Dependence on a single provider can lead to difficulties in switching vendors or adopting new technologies.
- Risk of Outages: An outage or issue with the provider affects all your services, which could lead to significant disruptions.
- Limited Flexibility: Less flexibility in choosing the best solutions or technologies for specific needs.
- Security Risks: A single point of failure can be a security risk if the provider experiences a breach and service disruptions.
- Neglected Competition: Less opportunity to leverage competitive pricing or innovative features from other providers.
Pros of Multi-Cloud:
- Reduced Risk of Outages: Distributes risk across multiple providers, reducing the impact of an outage or failure.
- Flexibility: Ability to choose the best services or technologies from different providers to meet specific needs.
- Avoid Vendor Lock-In: Easier to switch providers or negotiate better terms by avoiding dependence on a single vendor.
- Avoid SPOF: Reduces the risk associated with a single point of failure, distributed risk and enhanced resilience.
- Optimized Costs: Potential to optimize costs by using different providers for different services based on pricing and performance.
Cons of Multi-Cloud:
- Complexity: More complex to manage multiple cloud environments, including billing, integration, and interoperability.
- Increased Costs: Potentially higher costs due to lack of volume discounts, network i/o and increased administrative overhead.
- Integration Challenges: Difficulties in integrating and managing services across different cloud providers.
- Management Overhead: More effort required for monitoring, maintaining, and troubleshooting across various platforms.
- Data Transfer Costs: Higher costs and potential performance issues when transferring data between different cloud providers.
In the end, our choice depends on our specific needs and risk tolerance. Balancing simplicity and reliability is the key.
How to avoid such incidences ?
To prevent issues like the Microsoft outage caused by the CrowdStrike update, we need to adopt several strategies.
First, thorough testing is crucial. Before rolling out any software update, we should conduct extensive tests in various environments to catch potential problems.
Next, backup systems and rollback strategies are essential. Keeping regular backups allows us to revert to previous versions quickly if an update causes issues.
Communication with users is also key. Informing them about upcoming updates and possible downtimes helps manage expectations and reduce frustrations.
We should adopt a phased rollout approach. By releasing updates gradually, we can monitor for any problems and address them before they affect a larger number of users.
Monitoring and incident response plans are important. Having a dedicated team to monitor the rollout and respond quickly to issues can minimize the impact.
And, relying on reputable software providers and ensuring regular audits of third-party updates can help maintain system integrity and security.
By following these steps, we can significantly reduce the likelihood of facing similar incidents in the future.
Conclusion
The Microsoft outage due to Crowdstrike update on July 19, 2024, revealed the weaknesses in our digital systems and the real-world impact of these failures.
Despite the disruptions, it also showed how tech companies can quickly address and fix complex problems.
Moving forward, this incident serves as a reminder of the need to improve update processes and enhance system resilience.
By learning from this event, we can better appreciate the continuous efforts required to keep our technology secure and reliable.
Indeed, all such updates must be tested thoroughly before deployment to avoid disruptions